
Semantic clustering is the only viable method for organizing keyword lists at the 100k+ scale without exhausting your entire marketing budget on SERP APIs. While analyzing search engine results pages is the gold standard for matching current output, leveraging Natural Language Processing (NLP) to calculate the mathematical distance between meanings allows you to build a comprehensive advanced keyword research strategy for massive catalogs in a fraction of the time.
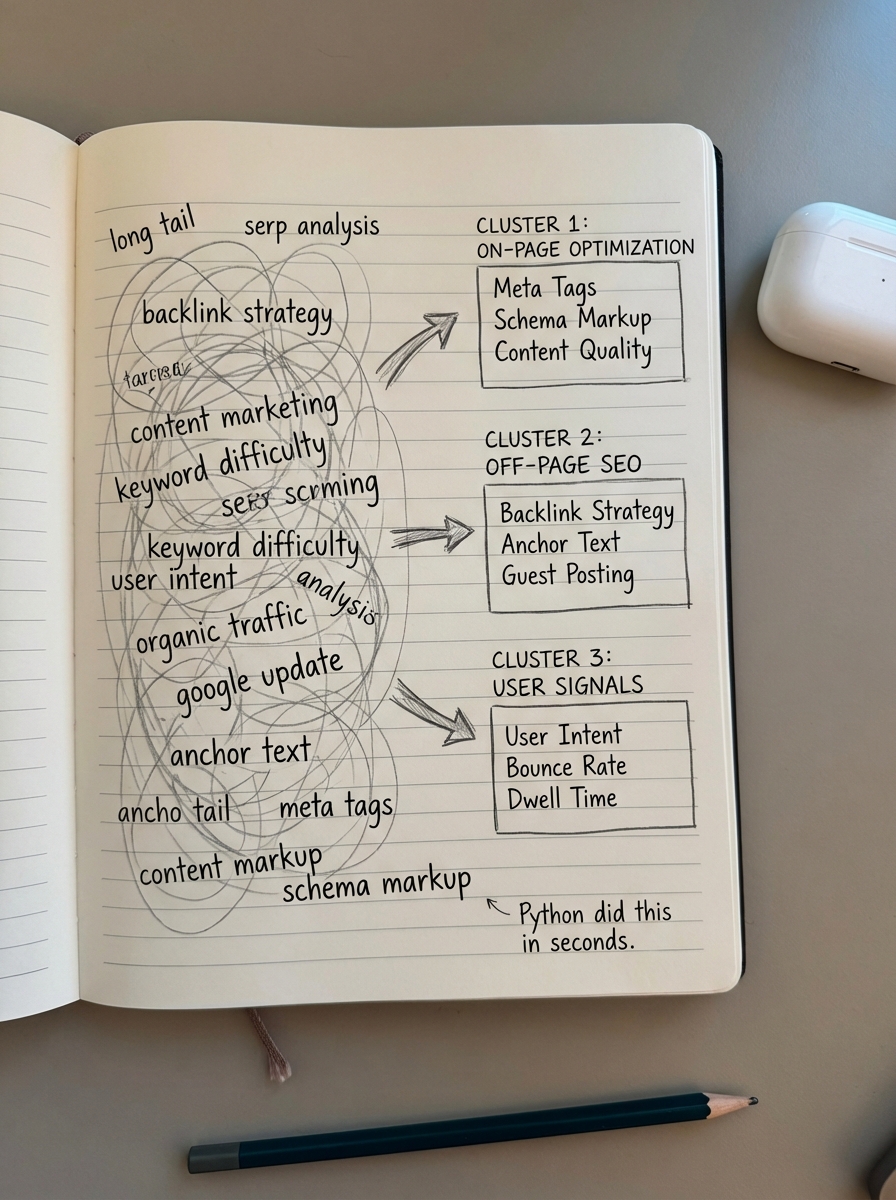
Why semantic clustering beats manual grouping
Manual keyword grouping is a relic of a bygone era in SEO. If you are still moving rows in a spreadsheet to group “running shoes for men” with “men’s sneakers for running,” you are wasting billable hours on a task that Python handles in seconds. In my experience, the primary objection to automated clustering is a perceived lack of accuracy; people worry that an algorithm won’t understand the specific nuances of their niche.
In reality, modern transformer models and LLMs understand semantic relationships with more consistency than a human specialist. By adopting keyword clustering machine learning, you move beyond simple word matching toward sophisticated concept mapping. This is critical for WooCommerce stores where the relationship between product attributes – like material or size – and buyer intent defines your site’s topical authority.
The technical stack: Python and NLP libraries
To cluster at scale, you need a programmatic environment. My go-to stack involves Python because of its robust data science ecosystem. I’ve found that Sentence-Transformers (SBERT) is indispensable because it produces dense vector embeddings that capture the context of an entire phrase, rather than just isolated words. For the mathematical heavy lifting, I use Scikit-learn for clustering algorithms, or I opt for HDBSCAN when I want to find clusters based on density without pre-defining the number of groups.
![]()
If I am working on a high-stakes project where accuracy is paramount, OpenAI embeddings are an incredibly cost-effective choice. Models like text-embedding-3-small offer higher dimensions than most open-source alternatives, allowing for more granular grouping. I typically use a hybrid approach that weighs semantic vs. SERP clustering based on the keyword value. I use semantic clustering to prune massive lists into broad buckets and then use a free SERP keyword clustering tool to validate high-value clusters where search intent might be ambiguous.
Practical workflow for clustering 100k keywords
When I build content plans for enterprise WooCommerce stores, I follow a four-step automated workflow that prioritizes speed and semantic relevance. The first step is vectorization, where I convert the keyword list into numerical vectors. I find that the all-MiniLM-L6-v2 model provides an excellent balance between speed and performance for most e-commerce datasets.
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('all-MiniLM-L6-v2')embeddings = model.encode(keyword_list)Beyond vectorization, the process requires dimensionality reduction and precise clustering. High-dimensional data is notoriously difficult to cluster efficiently, so I use UMAP (Uniform Manifold Approximation and Projection) to compress the vectors into 5–10 dimensions. This preserves the local semantic structure while significantly speeding up the computation.
I then apply Agglomerative Clustering with a strict distance threshold to ensure keywords are only grouped if their cosine similarity is extremely high. The final step involves intent labeling and centroid extraction. By finding the keyword closest to the mathematical center of each cluster, I can identify the primary pillar topic, while everything else in the group becomes a supporting long-tail variation.
Structuring WooCommerce category and blog content
Once the clusters are formed, the next challenge is translating that data into a logical site structure. A common mistake in the WooCommerce space is over-optimizing individual product pages while leaving category names vague. Most stores would see an immediate benefit from using more specific category names, such as “Waterproof Trail Running Shoes” instead of a generic “Shoes” label. You can use our free ecommerce category optimizer to identify where your current taxonomy fails to match your newly discovered semantic clusters.
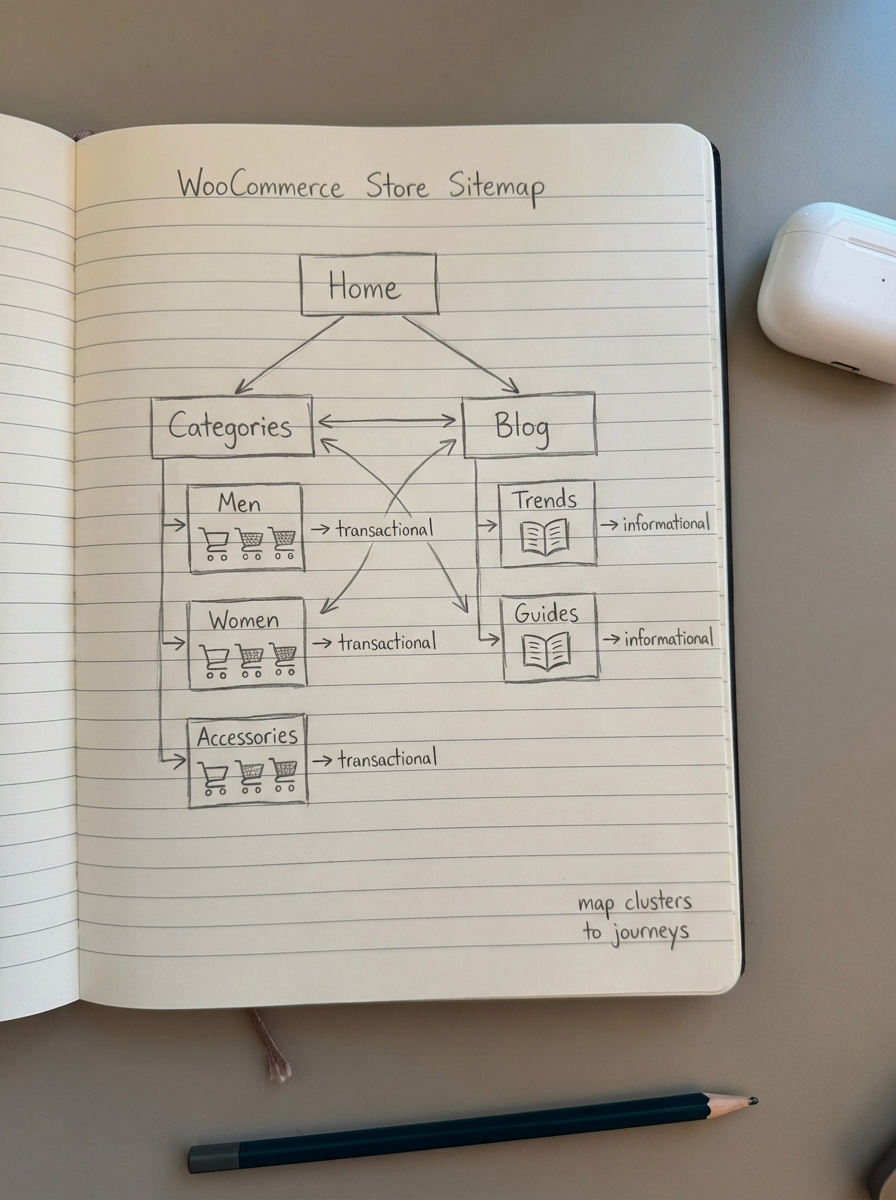
Map clusters to the buyer journey
I divide these clusters into two distinct paths based on intent. Transactional clusters, which often include high-intent modifiers like “buy” or specific SKUs, should be mapped directly to your WooCommerce product categories. Informational clusters, on the other hand, belong on the blog. For example, a cluster centered on “how to clean suede boots” should lead to a how-to guide that links back to your relevant product cleaning kits.
Managing these connections manually is a nightmare for stores with thousands of products. We developed the ContentGecko WordPress connector to solve this problem by automatically syncing your catalog to your blog content. This ensures that your internal linking stays accurate even as product slugs change or items go out of stock.
Handling the scale of enterprise SEO
At the enterprise level, where catalogs exceed 10,000 products, execution is usually the primary bottleneck. You might identify 500 high-value semantic clusters, but manually writing 500 articles could take years. This is where AI has truly disrupted the field. By combining entity-based keyword research strategies with our free AI SEO content writer, you can launch an MVP version of your entire blog strategy in just a few weeks.
I always recommend iterating on content like a product. Publish the AI-generated clusters first to establish your presence, then monitor your ecommerce SEO dashboard to see which topics gain traction. Once you see a cluster starting to rank, you can have a human editor polish the top performers to maximize conversions. This approach allows you to achieve coverage first and quality second, which is the most efficient way to scale organic traffic.
TL;DR
Semantic keyword clustering via Python and NLP is the most cost-effective solution for keyword research workflow optimization at scale. By using SBERT and HDBSCAN, you can organize over 100k keywords into intent-based groups, map transactional terms to optimized category pages, and use ContentGecko to automate the deployment of your blog strategy. Focusing on broad category optimization rather than individual product pages remains the fastest way to drive meaningful ranking improvements for WooCommerce.