
January 20, 2026
Structuring ecommerce data for LLM retrieval and RAG

A Retrieval-Augmented Generation (RAG) system is only as effective as the data architecture it sits upon. For WooCommerce merchants, this means moving beyond dumping a CSV of product descriptions into a vector database and expecting the LLM to understand the nuances of your catalog.
I have found that the difference between a “hallucination-prone” AI and a high-performing retrieval system lies in how you transform semi-structured ecommerce data – like product attributes, category hierarchies, and search logs – into a format that prioritizes semantic context over raw text. If you want to build a system that can accurately answer “Which waterproof hiking boots under $150 are best for wide feet?”, you need a specific pipeline for data transformation.
The ecommerce knowledge schema: Beyond flat tables
Most RAG implementations fail because they treat every piece of data as a generic “document.” In ecommerce, data is inherently relational. Critics often argue that LLMs can “figure out” relationships on their own if the context window is large enough, but in practice, this leads to significant reasoning errors when navigating deep product taxonomies. To make this usable for an LLM, you must define a schema that preserves these relationships.
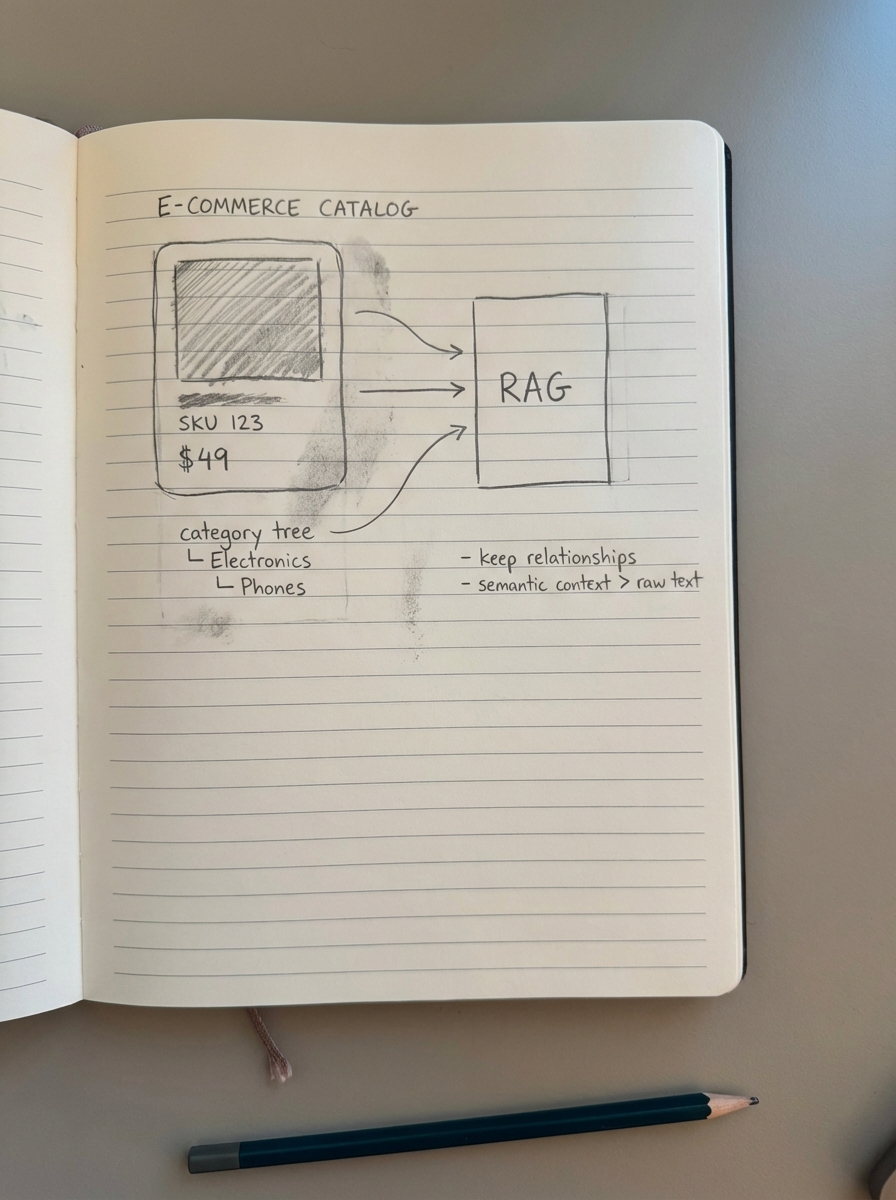
I recommend a three-tier data model for WooCommerce retrieval:
- Product Entities: These include the “hard” specs such as SKU, price, stock status, and attributes like material or dimensions.
- Contextual Metadata: This includes the hierarchical site structure and breadcrumb paths. This provides the necessary signals for the LLM to understand that a “Road Bike” is a subset of “Cycling,” which is a subset of “Outdoor Sports.”
- Behavioral Data: This is the most overlooked component. By ingesting your internal search logs, you can map common user queries to specific product clusters, essentially teaching the LLM which products “solve” specific problems.
When we build catalog-aware content at ContentGecko, we ensure the underlying JSON-LD or schema mirrors this structure. Without it, the LLM loses the “why” behind the product, failing to grasp the intent that traditional SEO has long prioritized.
Chunking strategies for product catalogs
Standard recursive character splitting often breaks the most important data in an ecommerce catalog. If you split a chunk in the middle of a technical specification table or a SKU list, the embedding model loses the relationship between the attribute and the product. While some developers argue for massive chunks to capture more context, this often introduces noise and dilutes the semantic signal of the specific product being queried.
Semantic chunking by object
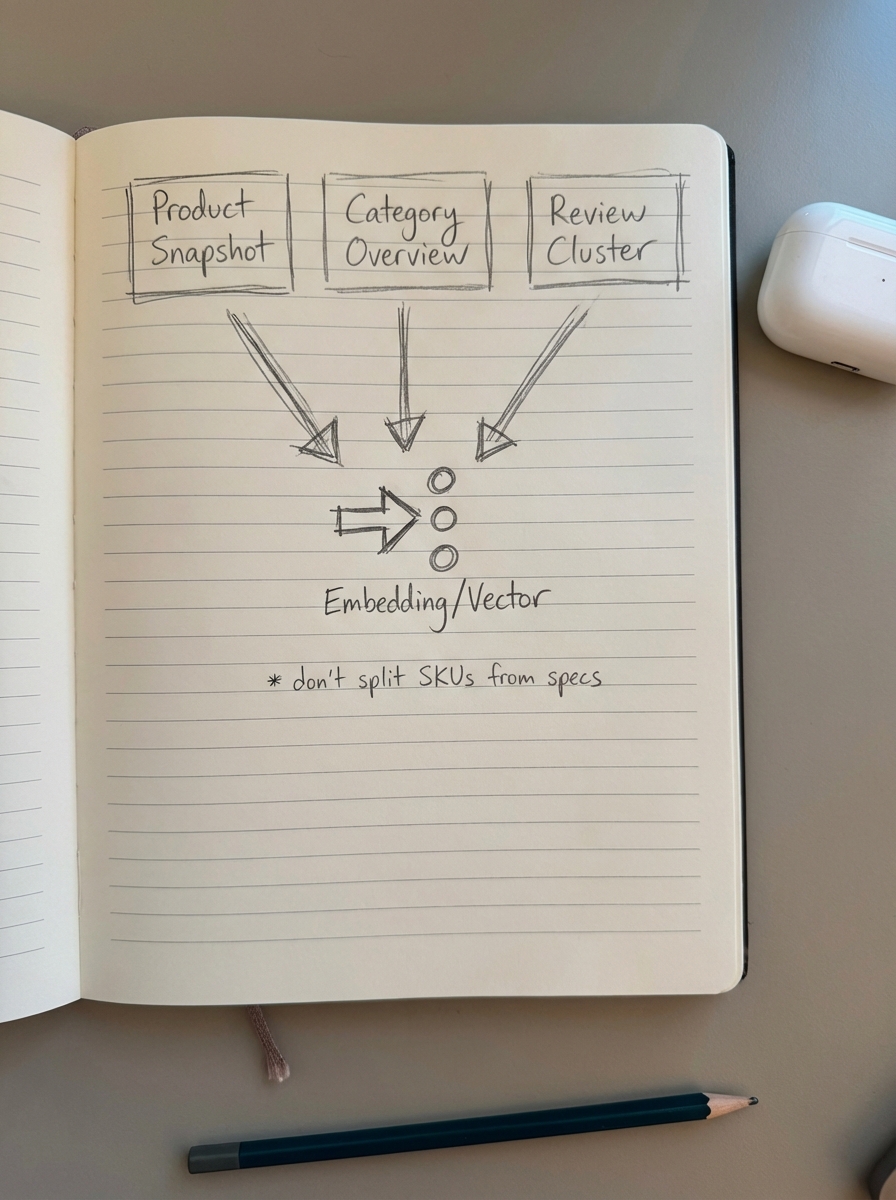
Instead of fixed token lengths like 512 or 1024, I advocate for semantic chunking. For WooCommerce, a single chunk should ideally represent a complete logical unit to maintain data integrity.
- A Product Snapshot: This should contain the product name, SKU, short description, and all key attributes.
- A Category Overview: This encompasses the category name, parent category, top five best sellers, and common use cases.
- A Review Cluster: This involves grouping three to five high-quality customer reviews by sentiment or specific use cases to provide the LLM with social proof context.
The “Overlapping Specs” pattern
If your architecture requires fixed-size chunks, you should implement a 15-20% overlap. However, the critical step is ensuring that the “Product Title” and “Primary Category” are prepended to every single chunk. This ensures that even if a chunk focuses on “Washing Instructions,” the retriever still knows it belongs to a “Premium Merino Wool Sweater,” preventing the LLM from losing the thread during high-concurrency retrieval tasks.
Embeddings and metadata filtering
Vector embeddings allow for semantic search, but they are notoriously bad at handling “hard” filters like price or stock status. If a customer asks for “boots under $100,” a pure vector search might return a $120 boot because the description is highly relevant. Skeptics often believe that better embedding models will eventually solve this, but the mathematical reality of vector space makes precise numerical filtering difficult for LLMs today.
This is why effective metadata strategies for LLMO are non-negotiable. You should store your vectors in a database – such as Pinecone, Weaviate, or Milvus – alongside structured metadata fields.
I suggest focusing on several specific metadata fields for WooCommerce RAG:
price_numeric: This allows for essential range filtering during the query phase.in_stock: A boolean field to prevent the system from recommending unavailable items.category_slug: This enables scoped searches within specific silos.average_rating: This helps the system prioritize high-quality results in the initial retrieval step.
By using metadata filtering, you narrow the search space before the LLM even sees the data. This drastically reduces hallucinations and improves overall LLM search performance.
The hybrid retrieval pipeline
I have found that the most reliable ecommerce RAG systems do not rely solely on vector search. Instead, they use a hybrid search pipeline that combines the precision of traditional methods with the intuition of modern AI.
The process begins with Keyword Search (BM25), which is excellent for finding specific SKUs, brand names, or technical terms that embedding models might inadvertently “smooth over.” Next, Vector Search handles the “vibes” and broad intent, such as queries for “shoes for a summer wedding.” Finally, a Reranking step uses a secondary model, like a Cross-Encoder, to look at the top results from both searches and re-order them based on their actual relevance to the user’s specific prompt.
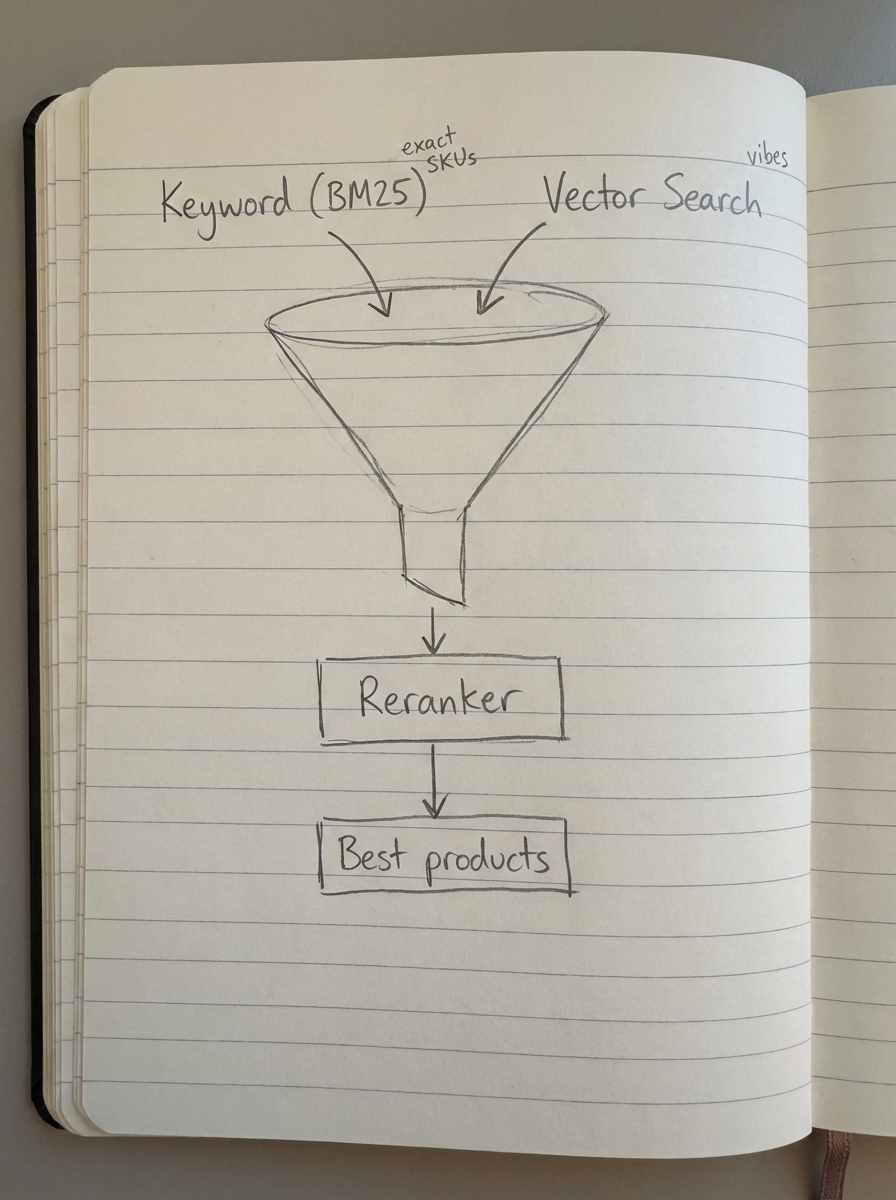
This pipeline ensures that if someone searches for a specific part number in your WooCommerce store, they actually find it, while still allowing for the conversational discovery that modern AI users expect.
Syncing the catalog with the retrieval layer
The biggest challenge for WooCommerce stores is data freshness. Prices change, items go out of stock, and new categories are optimized. If your RAG system is searching a 3-month-old index, it is useless for driving conversions. Many merchants assume that a weekly re-indexing is enough, but in a fast-moving store, this lag results in a poor user experience.
At ContentGecko, we solve this through a WordPress connector plugin that treats the product catalog as a live feed. When we generate blog content or buyer guides, our system pulls the current state of the catalog to ensure the internal links and product recommendations are accurate and synchronized with the latest inventory.
If you are building this in-house, you should implement a webhook-based update system. Every time a product_update event triggers in WooCommerce, your pipeline should re-embed that specific product chunk and update the vector store in real-time. This dynamic approach is the cornerstone of a successful Large Language Model Optimization strategy.
TL;DR
To make ecommerce data LLM-ready, move away from flat document storage in favor of a relational schema that preserves product attributes. Implement semantic chunking that never splits a SKU from its description, and use metadata filtering to handle “hard” constraints like price and stock levels. Finally, adopt a hybrid retrieval approach that combines traditional keyword matching with vector search to ensure both precision and semantic understanding. Integrating these steps ensures your AI strategy translates into actual sales.