
Shipping an LLM-powered product advisor is relatively straightforward, but keeping it from hallucinating outdated prices or recommending out-of-stock SKUs to thousands of shoppers is where the real engineering starts. If you aren’t monitoring the delta between your live product catalog and your model’s outputs, you aren’t running a production system – you’re running a liability.
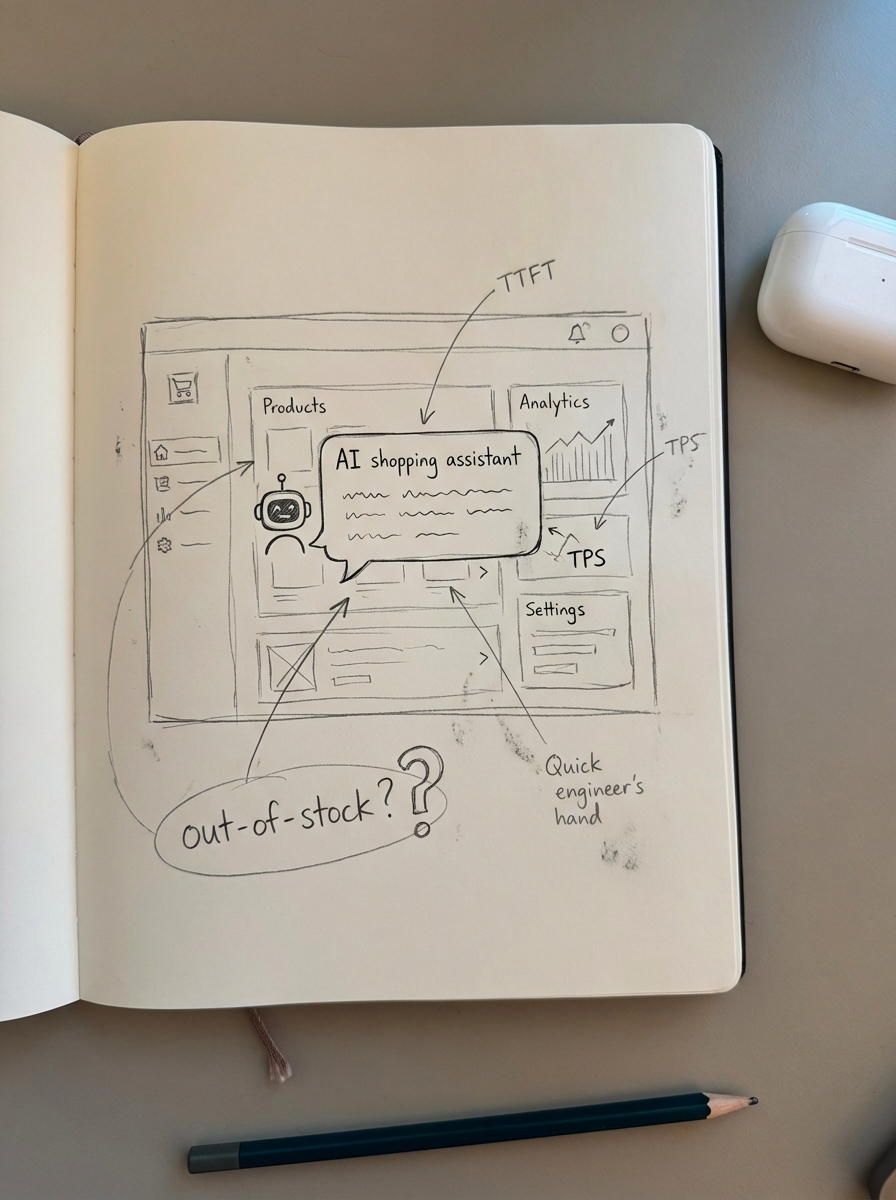
Core metrics for production LLM observability
In a standard microservices architecture, P99 latency is often the primary concern. In LLM systems, we have to look deeper into the generation lifecycle to understand the user experience. For ecommerce shoppers, speed is a direct conversion factor; if your AI shopping assistant takes three seconds of dead silence before it starts typing, the user has already bounced to a competitor.
- Time to First Token (TTFT): This is the most critical metric for perceived speed. It measures the latency between a user query and the first visible character of the response.
- Tokens Per Second (TPS): This helps measure overall throughput and identifies bottlenecked inference providers or inefficient prompt structures.
- Cost per Request: With LLM search expected to drive 75% of search-related revenue by 2028, tracking token consumption at the SKU or category level is the only way to ensure your AI features maintain positive unit economics.
- Retrieval Precision and Recall: For RAG systems, you must monitor how often the retrieved context actually contains the necessary answer. Structuring data for LLM retrieval is a moving target as your product catalog grows, making these metrics essential for maintaining accuracy.
LLM-as-a-judge and the evaluation loop
Manual labeling and human review do not scale for an enterprise WooCommerce store with 10,000 or more products. To solve this, I recommend the “LLM-as-a-judge” pattern. This involves using a more powerful, “smarter” model, such as GPT-4o, to programmatically score the outputs of your smaller, cheaper production models like Llama 3 or Claude Haiku.
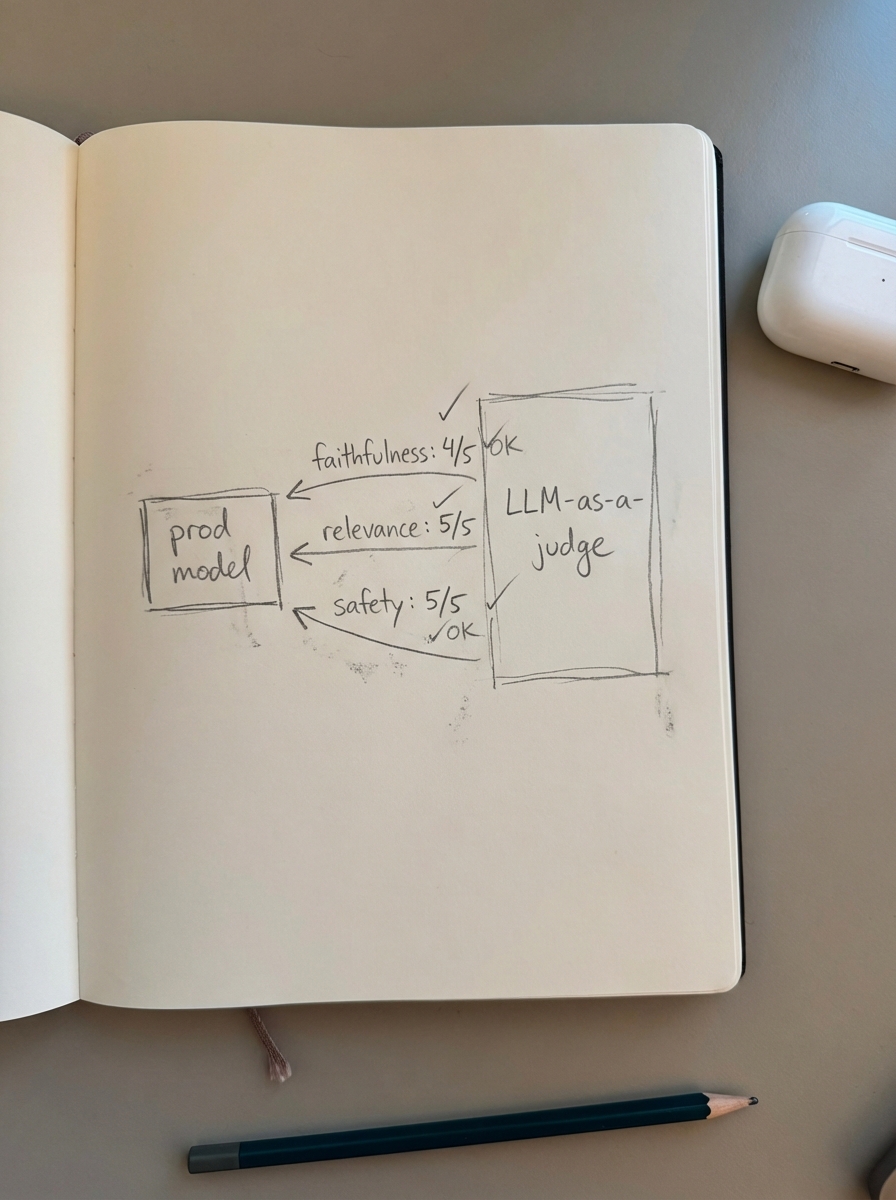
We primarily evaluate three dimensions of quality. First is faithfulness, which determines if the model strictly adhered to the provided product metadata without inventing features. Second is relevance, ensuring the model actually addressed the shopper’s specific needs. Measuring user intent in LLMO search is the fundamental difference between a high bounce rate and a completed purchase. Finally, we monitor for toxicity and safety to ensure the model doesn’t generate inappropriate content or leak sensitive internal data like wholesale margins.
Modern platforms allow you to unify this process by converting production traces into test cases with a single click. This creates a critical engineering flywheel where your production failures automatically become the baseline for your next CI/CD test suite.
Tooling landscape: Monitoring vs. observability
I find that many engineers still confuse simple logging with true observability. If your system logs a generic error but cannot explain why a model hallucinated a price that hasn’t existed in your database for six months, you do not have observability.
Braintrust has emerged as a gold standard for teams that want to bridge the gap between initial testing and live production. It handles online scoring with configurable sample rates and generates evaluation datasets directly from production logs. This level of oversight is critical when you are managing a complex LLMO tool stack that may involve multiple inference providers and RAG pipelines.
Other specialized tools like LangSmith excel at tracing complex chains, particularly when an ecommerce agent must query a vector database, check a SQL inventory database, and synthesize a response. These tools provide the nested traces needed to identify the specific node in the chain that failed. Additionally, platforms like WhyLabs or Arize Phoenix focus on “data-centric” AI, which is useful for detecting semantic drift. If shoppers suddenly start asking about a new viral trend and your model’s embedding space isn’t prepared to handle it, these platforms can alert you before your conversion rates take a hit.
Ecommerce failure modes and catalog drift
The most common technical SEO mistake in ecommerce is a bloated, stale website, and this problem translates directly to LLM performance. When prices, stock levels, or URLs change in your WooCommerce store, your vector database must stay perfectly in sync. If your monitoring does not catch a misclassified product category, your RAG system will retrieve the wrong context, leading to high-confidence hallucinations.
At ContentGecko, we solve this by providing a catalog-synced platform designed specifically for high-volume stores. We do not just generate static content; we continually update it as your SKUs and stock levels change. Our WooCommerce connector plugin ensures that the context being fed to search engines and LLMs is always accurate, effectively eliminating the catalog drift that typically kills RAG performance in production.
Incident response and CI/CD integration
Monitoring is only as good as the actions it triggers. Your LLM observability stack should be integrated directly into your GitHub Actions or GitLab CI to prevent regressions before they reach your customers. Every pull request should run a subset of your LLM-as-a-judge scorers; if a prompt change reduces faithfulness by even a small margin, the build should fail.
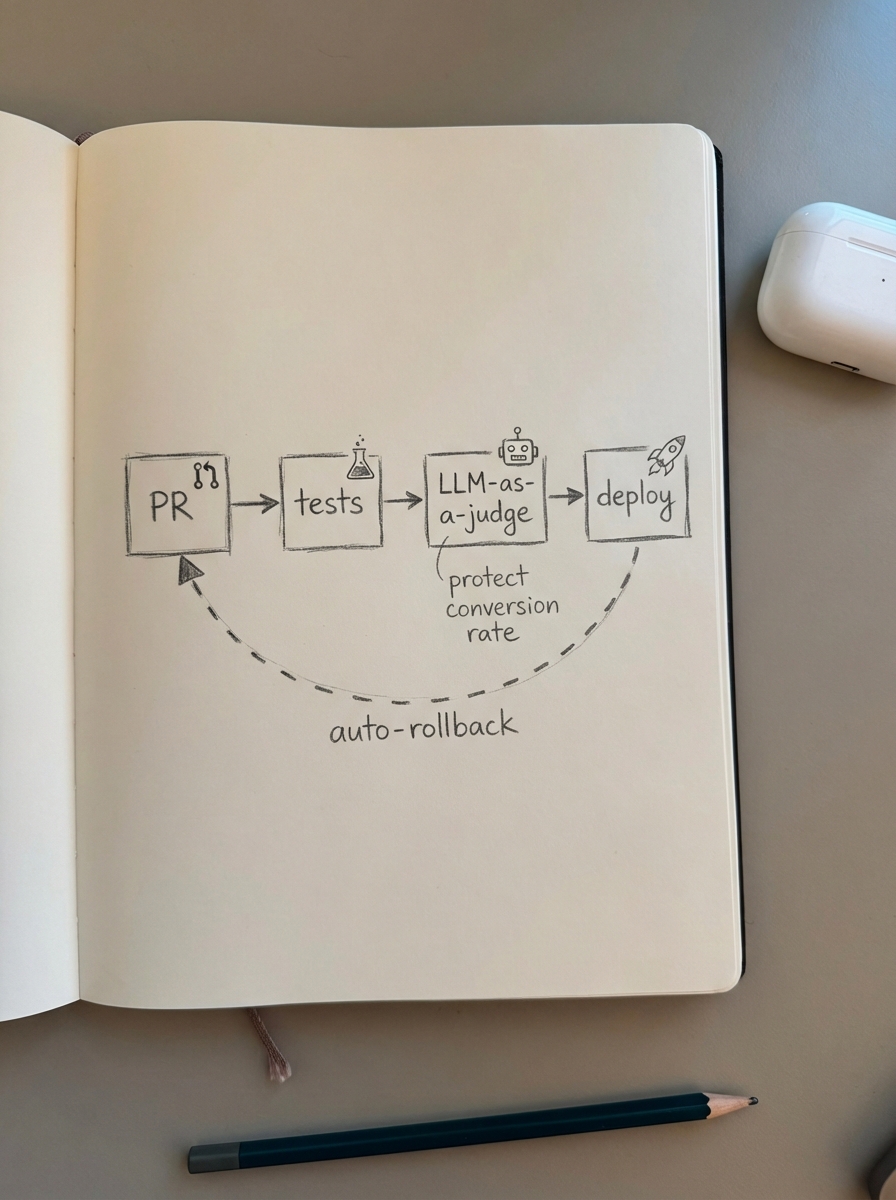
I also suggest using traffic splitting for A/B testing, allowing you to compare a new fine-tuned model against your baseline in the wild. During these tests, you should track conversion rates from LLMO traffic as your primary success metric. Finally, implement automatic rollbacks. If your production safety filters or hallucination checks trigger at a rate significantly higher than your baseline, the system should automatically revert to a known stable prompt version or model.
TL;DR
Effective LLM monitoring for ecommerce requires shifting from basic operational metrics like latency to quality-centric metrics like faithfulness and relevance. You should implement an “LLM-as-a-judge” pattern to automate scoring at scale and use a unified platform for production tracing. For WooCommerce merchants, using ContentGecko automates the synchronization between your product catalog and your LLM-optimized content, ensuring your production outputs remain accurate, safe, and conversion-focused without requiring constant manual oversight.