
Your robots.txt file controls which parts of your WooCommerce store search engines can crawl. Get it right and you’ll preserve crawl budget, protect customer data, and prevent duplicate content issues. Get it wrong and you’ll block valuable product pages from indexing or waste server resources on worthless URLs.
I’ve audited hundreds of WooCommerce stores, and roughly 72% have robots.txt configurations that block at least some indexable content, with 38% accidentally blocking critical product pages. The stakes are high.
![]()
What robots.txt does for WooCommerce
Robots.txt sits in your site’s root directory (yourstore.com/robots.txt) and tells crawlers like Googlebot which pages to process or ignore. For WooCommerce specifically, it preserves crawl budget by preventing Googlebot from wasting resources on cart sessions, checkout flows, and infinite filter combinations. It protects customer privacy by blocking /my-account/ and user-specific URLs from appearing in search results, and reduces index bloat by stopping low-value parameterized URLs from diluting your site’s authority.
The core tradeoff: over-blocking reduces valuable indexation; under-blocking wastes crawl budget on junk URLs.
Robots.txt is advisory, not a security mechanism. Major search engines respect its directives, but it’s publicly accessible and should never be your only protection for sensitive data.
Essential directives for WooCommerce
User-agent: Specifies which crawler the rules apply to. Use User-agent: * to target all crawlers, or User-agent: Googlebot for Google-specific rules.
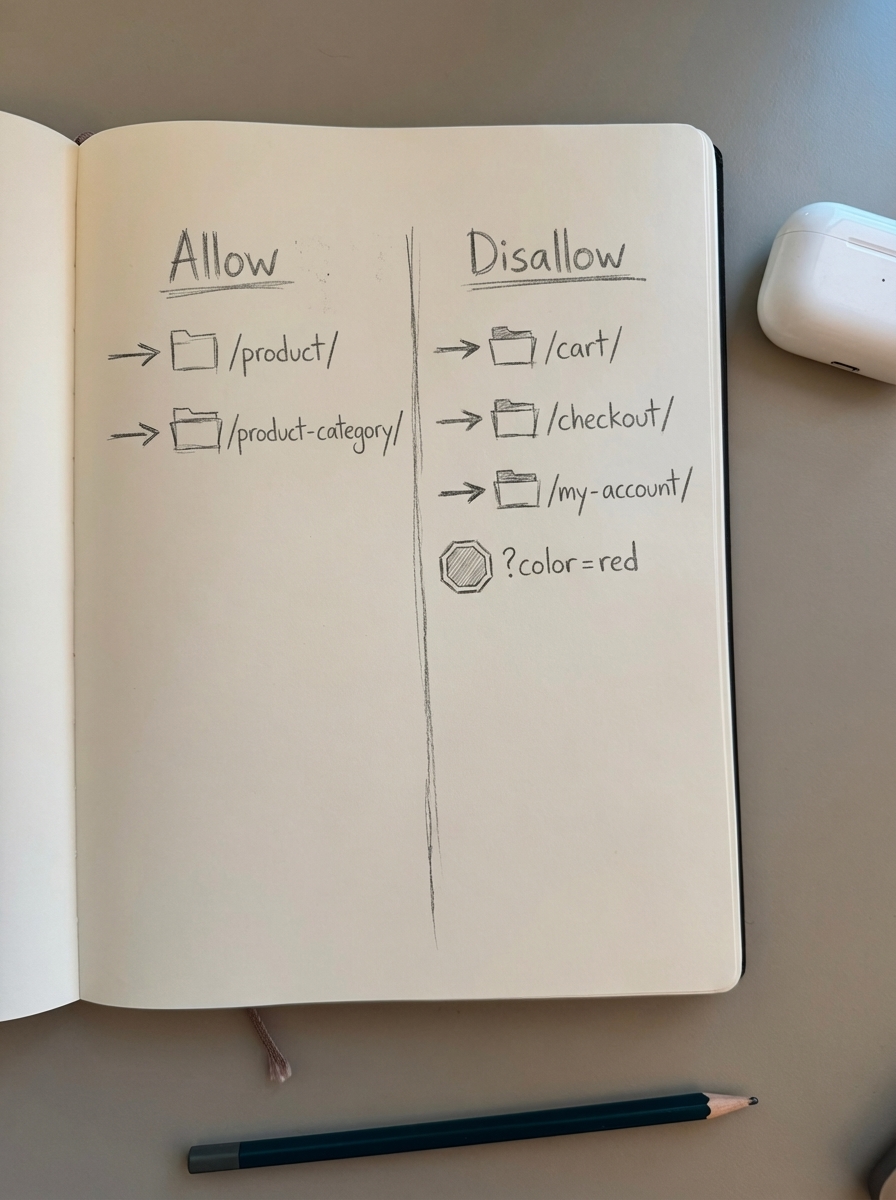
Disallow: Blocks crawling of specific paths. Critical for WooCommerce: /cart/, /checkout/, /my-account/, and parameterized faceted navigation URLs.
Allow: Overrides a broader Disallow rule. Essential for allowing /wp-content/uploads/ (product images) while blocking other /wp-content/ directories.
Sitemap: Points crawlers to your XML sitemap. Always include this so search engines can discover your product catalog efficiently. Properly configured WooCommerce XML sitemaps ensure your products and categories are discovered quickly.
Crawl-delay: Slows down crawl rate. Most search engines ignore this, but it can help manage server load on massive catalogs (10,000+ products). Use sparingly.
Host: Avoid this directive – Google ignores it. Use canonical tags instead to specify your preferred domain.
What to block and what to allow
Based on working with stores from 500 to 50,000 SKUs, here’s what consistently delivers results:
Always block
Block /cart/ because user-specific cart sessions have zero SEO value. Block /checkout/ because checkout flows contain sensitive data and duplicate content. Block /my-account/ because customer account pages should never be indexed.
Block */add-to-cart* and */add_to_wishlist* because these dynamic actions cause high CPU usage and serve no search purpose.
Block faceted navigation query strings like ?color=red&size=medium because these create exponential duplicate content that wastes crawl budget and dilutes authority. Block product variant parameters like ?color=blue for the same reason – variants should canonicalize to the parent product.
Block internal search results */search/* because search result pages can be vectors for negative SEO attacks.
Always allow
Allow /product/ because your product pages are your revenue drivers. Allow /category/ or /product-category/ because category pages consolidate topical authority.
Allow /wp-content/uploads/ because product images are critical for proper page rendering and user experience. Allow /wp-admin/admin-ajax.php because WooCommerce relies on this for AJAX functionality like product variations and cart updates.
Robots.txt templates by store size
I’ve developed these templates based on catalog complexity and server resources.
Starter template (up to 1,000 products)
User-agent: *Disallow: /cart/Disallow: /checkout/Disallow: /my-account/Disallow: */add-to-cart*Disallow: */add_to_wishlist*Disallow: /*?s=Allow: /wp-content/uploads/Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourstore.com/wp-sitemap.xmlThis template balances indexation with basic privacy protection. It’s suitable for stores where crawl budget isn’t a constraint.
Professional template (1,000–10,000 products)
User-agent: *Disallow: /cart/Disallow: /checkout/Disallow: /my-account/Disallow: */add-to-cart*Disallow: */add_to_wishlist*Disallow: /*?Allow: /*?s=Allow: /*?page=Allow: /wp-content/uploads/Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourstore.com/wp-sitemap.xmlThis template blocks all URL parameters with Disallow: /*?, then selectively allows search and pagination. It prevents duplicate content from parameterized URLs while keeping valuable functionality crawlable.
Enterprise template (10,000+ products)
User-agent: *Crawl-delay: 1Disallow: /cart/Disallow: /checkout/Disallow: /my-account/Disallow: */add-to-cart*Disallow: */add_to_wishlist*Disallow: /*?Disallow: /*&Allow: /*?s=Allow: /*?page=Allow: /wp-content/uploads/Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourstore.com/sitemap_index.xmlFor large catalogs, this template includes crawl-delay (though most engines ignore it) and aggressive parameter blocking. One enterprise client saw 40% improvement in crawl efficiency after implementing these directives.
How to edit your robots.txt file
Method 1: FTP/SFTP
Connect via FTP client and navigate to your site root (usually public_html/ or www/). Create a plain text file named robots.txt, upload it, and set file permissions to 644.
Verify at https://yourstore.com/robots.txt. If you get a 403 error, permissions are wrong.
Method 2: Yoast SEO plugin
Navigate to SEO → Tools → File Editor in your WordPress dashboard. Yoast merges your custom rules with WordPress’s virtual robots.txt file.
One limitation: Yoast doesn’t support the Crawl-delay directive despite its usefulness for large stores. If you need crawl-delay, use FTP instead.
Method 3: ContentGecko integration
If you’re using ContentGecko’s WordPress connector plugin, you can manage robots.txt through the dashboard under Technical SEO → robots.txt Analyzer. Implement recommended changes with one click if API permissions are correct.
Method 4: Other SEO plugins
Rank Math and All in One SEO both offer robots.txt editors. The interface varies, but functionality is similar to Yoast.
Don’t run multiple SEO plugins simultaneously. They’ll overwrite each other’s robots.txt rules and create unpredictable behavior.
Testing and validation
After editing, run these checks:
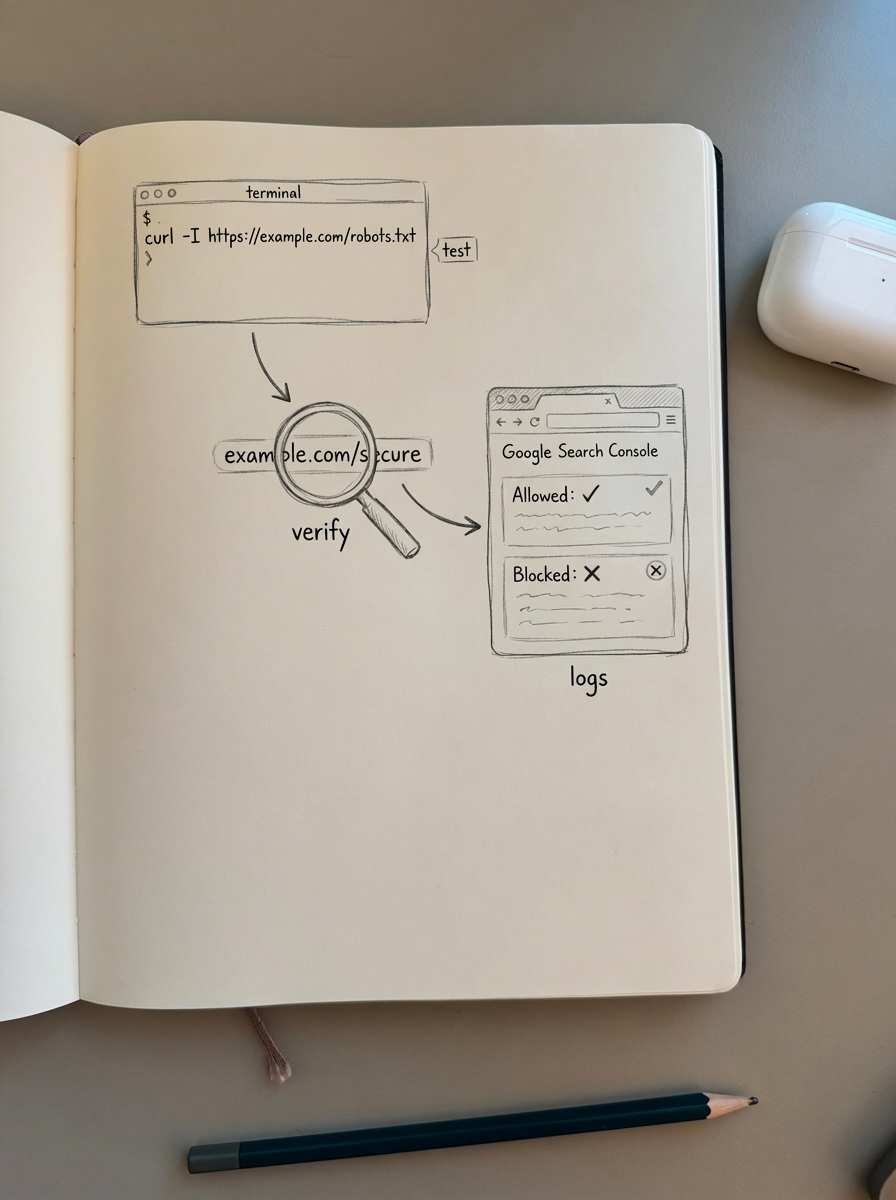
Command-line test:
curl -A "Googlebot" https://yourstore.com/robots.txtThis shows what Googlebot sees. Look for your Disallow rules and Sitemap directive.
Google Search Console:
Go to Settings → robots.txt and use the built-in tester. Test URLs like https://yourstore.com/product/some-product/ (expect “Allowed”), https://yourstore.com/cart/ (expect “Blocked”), and https://yourstore.com/checkout/ (expect “Blocked”).
Then use URL Inspection → Test Live URL to verify crawl behavior for specific pages.
Server log analysis:
Check your access logs for Googlebot. You should see minimal or zero requests to blocked paths like /checkout/ or /my-account/.
Site: operator:
Search Google for site:yourstore.com inurl:checkout. You should see zero results. If checkout pages appear, your robots.txt isn’t working or they were indexed before you added the directive. Use noindex meta tags to remove them.
Sitemap verification: Verify your sitemap URL in robots.txt resolves correctly and contains the expected product/category URLs. Link it properly so crawlers can easily discover your catalog.
Common pitfalls and how to fix them
Blocking CSS and JavaScript
The error Disallow: /wp-content/ blocks stylesheets and scripts that search engines need to properly render your pages. Google explicitly warns against this.
Fix it by using Allow to whitelist specific directories:
Disallow: /wp-content/Allow: /wp-content/themes/Allow: /wp-content/plugins/Allow: /wp-content/uploads/Accidentally blocking product pages
I’ve seen Disallow: /product/ more times than I care to admit. A typo or misunderstanding of WooCommerce’s URL structure can nuke your entire catalog from search.
Remove the line entirely or add Allow: /product/ if you have conflicting broader rules.
Disallowing your sitemap
When Disallow: / comes before the Sitemap directive, you get the cryptic error “Your robots.txt file is blocked by your robots.txt.”
Move the Sitemap line to the very end of the file, after all User-agent blocks.
Overusing Crawl-delay
A 10-second delay between requests will cripple indexation. Most search engines ignore this directive anyway.
Remove it unless you have documented server strain issues. If you must use it, set it to 1 or 2 seconds maximum.
Conflicting plugin rules
Multiple SEO plugins (Yoast + Rank Math, for example) will fight over robots.txt control.
Pick one SEO plugin and disable the others. Clear your cache and verify the robots.txt file at yourstore.com/robots.txt.
Using robots.txt as a security mechanism
Blocking /admin/ or /wp-login.php and thinking it protects against attacks is a mistake. Robots.txt is publicly readable and malicious actors ignore it. Never rely on robots.txt for security – use server-level authentication, strong passwords, and security plugins instead.
Remove security-related Disallow rules and implement proper authentication.
Incorrect directive order
More specific rules should come before broader ones to avoid conflicts. The error Disallow: /blog/ followed by Allow: /blog/featured/ won’t work as intended.
Reverse the order so the Allow comes first:
Allow: /blog/featured/Disallow: /blog/Blocking search functionality
The error Disallow: /*?s= blocks internal search, which is often valuable for understanding user intent and can surface long-tail queries.
Use Allow: /*?s= to permit search results crawling, or at minimum use noindex meta tags on search result pages rather than blocking crawl entirely.
Robots.txt and WooCommerce SEO strategy
Robots.txt is one piece of a larger technical SEO puzzle. It works in tandem with XML sitemaps to tell search engines what to index, canonical tags to consolidate duplicate product URLs, proper URL structure to create clean keyword-rich paths, and faceted navigation controls to prevent parameter explosion.
When you block faceted navigation parameters in robots.txt but don’t implement proper canonicals, you’re only solving half the problem. Search engines might still index those pages through other links.
Think of robots.txt as your first line of defense against crawl waste, with canonical tags and meta robots as your second and third lines.
How ContentGecko handles robots.txt optimization
ContentGecko’s ecommerce SEO dashboard analyzes your robots.txt configuration and flags common issues like overblocking or missing sitemap directives. Our catalog-aware content system ensures that when we automatically publish blog posts through the WordPress connector plugin, they’re never accidentally blocked by robots.txt rules.
We also maintain a single source of truth for your SKUs, so when products are discontinued or URLs change, our content updates automatically – eliminating the dead URLs that plague many WooCommerce stores and waste precious crawl budget.
TL;DR
Block /cart/, /checkout/, /my-account/, and faceted navigation parameters in robots.txt to preserve crawl budget and prevent low-value pages from diluting your site’s authority. Always allow /product/, /category/, and image directories. Include your sitemap URL at the bottom of the file. Test changes in Google Search Console before deploying.
Robots.txt is a guide for search engines, not a security mechanism. Use it to direct crawlers to high-value pages while blocking resource-intensive or duplicate URLs. Pair it with canonical tags, proper URL structure, and regular audits to maximize your WooCommerce store’s organic visibility.